
It's LLMs All The Way Down - Part 1
The most exciting time to explore a technology is when it's rapidly evolving

Posted by Matias Grynberg Portnoy
on August 6, 2024 · 6 mins read
👉 Smaller models are getting smarter
👉 More Standardization Everywhere
👉 Business show interests in incorporating LLMs
👉 Open Source is Catching up to Speed
Disclaimer: Some of the statements made on this post are forecasts based on currently available information. They could be rendered obsolete in the future or there could be a major change on the work and experiences of these technologies.
Introduction
Recent advances in LLMs (Large Language Models), image generation, and multimodality open up the gates for all sorts of applications. With new developments popping up on a daily basis, it's not enough to know where we are; we must know where we're headed. Yes, we need to predict the future. Why attempt such a thing? Now, besides doing it because it's cool, there's also some practical tangible reason: First-mover advantage is real and powerful. Being able to take part in a niche or sector as it is being formed while the competition is low is a very desirable thing and it gives you a head start for getting better. It's enough to take a look around. Here is one example:
- HuggingFace began working with natural language processing around 2016 before pivoting to providing a variety of AI and Machine Learning solutions way before LLMs hit it big. Back then, language models were smaller and more manageable but dumber and had limited capabilities. Nowadays, HuggingFace has become a top player in the AI space and has a $4.5 billion valuation.
Of course, it’s not just about arriving early. You need the technical expertise and resources to pull it off, and obviously, a bit of luck doesn’t hurt.
Predicting the future is challenging, but we can make educated guesses by observing current trends.
Let’s begin by assessing the current landscape.
Looking Around
Big players are moving their pieces, placing their bets. That can be taken as an indicator of the direction where we are heading.
As with previous technological shifts, we see a similar process to Evolutionary Radiation in which a species evolves to fill a multitude of available niches. That’s what we see in the tremendous effort put into LLMs, both from end-user applications to AI-optimized hardware.
Smaller Models are Getting Smarter
In recent years, the trend has been to build ever-larger LLMs. While this continues, there's also a push to make smaller, more efficient models. Why? Because these things are hardware-intensive! This means high infrastructure costs and limits on applications like running AI on user devices, such as phones, or even locally inside web browsers.
There are a variety of tricks like:
- Quantization model weights
- Dynamic swapping of specialized LoRAs
- Model distillation
- Specialized training schedules with curated datasets
- Pruning weights
...among many others actively researched to achieve this goal. Very specialized tiny models are also getting good results.
Some examples of all these efforts are (the names do not matter that much as in a very short while they will be beaten too):
- LLama3 (70b parameters) is beating the original ChatGPT3.5(175b). x2.5 reduction!
- SQLCoder (7b), a (relatively) small model for SQL query creation. Performance is comparable with GPT4 (~1.8 trillion parameters). x257 smaller!
- Phi-3-small (7B) is beating ChatGPT3.5 on some benchmarks. x75 tinier!
- Phi-3-vision (4.2B) performs comparatively well with much larger vision models like GPT-4V (~1.8t). x428 diminution!
So, we have a plethora of open models that perform well and are not that large. Fine-tuning them on a particular task can lead to superb results. Based on current results and research, there are a lot of reasons to believe that current LLMs are way below their capabilities for their respective computing. That is, given an LLM with, let’s say 20 billion parameters, future LLMs will be capable of doing much more, and less prone to errors.
More Standardization Everywhere
The ecosystem around LLMs is maturing. Things are moving from hard proof-of-concept custom builds to standardized production-ready systems. Deploying things while remaining secure and scalable is getting easier.
Take, for instance, Amazon Bedrock, AWS’s Gen AI solution. It offers API endpoints to run inference on a set of LLMs and image generation models. It’s serverless/SaaS, meaning you do not need to worry about your homemade production setups which are both expensive and complex.
However, if you do need a more customized setup, the server direction is also getting more standardized. Exemplified by NVIDIA NIM. It’s an inference-optimized way to scale AI applications in your own infrastructure. Huggingface has recently made it easier to deploy models with NIM.
This means running both standard models and customized ones is becoming easier every day.
There are more and more large competitive models available, so whatever direction you go, you have options. Nvidia themselves have recently published Nemotron-4-340B-Instruct. A really, really big LLM.
The maturity of the LLM ecosystem is highlighted by Model Spec, which outlines the necessary functionalities, performance metrics, and safety measures for deploying large language models. This standardization enhances compatibility, accelerates innovation, and reduces time to market for AI solutions, making adoption and scaling easier for organizations.

LLMs are the new UI/UX
Apple has recently been working on integrating LLMs with their phones (ref1 ref2). The basic premise is that the AI will be able to perform actions on your behalf based on natural language prompts from the user, hopefully fulfilling the promise of an actually useful virtual assistant.
Similar to this, Google Chrome is playing around with incorporating Gemini into your day-to-day browsing (ref1 ref2).
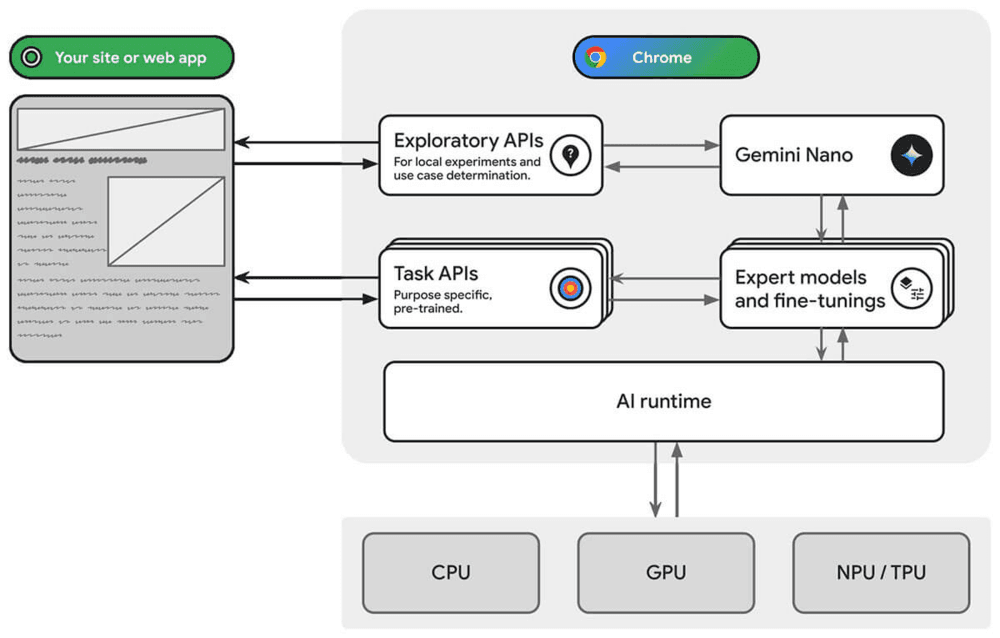
Microsoft's Copilot+PC is a standout. Its new Recall feature continuously captures your activity, making it easy to revisit documents or websites by describing what you were doing. Phi-3-Silica, from the small models we discussed, will be integrated into Copilot+PC, showing they're already moving in this direction locally. Note that this feature was not free of criticism for security and privacy reasons.
Countless companies, alongside major players, are integrating AI into their products for enhanced UI/UX. Zoom’s AI Companion is an excellent example of leveraging LLMs for your business case. It helps with a variety of tasks across the Zoom platform. Slack and ClickUp are doing the same to attract more users and offer higher-priced tiers.
Business Show Interest in Incorporating LLMs
Beyond the UI/UX perspective, businesses are showing interest in LLMs for various reasons. While there’s no lack of hype, LLMs are addressing real pain points. These include summarizing user feedback, generating ads, intelligently sifting through large document corpuses, teaching, assisting with analytical tasks, coding, reducing customer service costs, and more.
With such a wide range of applications, a surge of companies is emerging trying to hit those pain points in different markets. Also, the more traditional companies are beginning to incorporate these tools to improve the productivity of their workers. Not to mention people themselves going out of their way to use LLMs to make their jobs easier.
- Filevine is using LLMs to help lawyers be more productive. Extracting information from documents, making drafts, etc (ref).
- AWS is as of today previewing AWS app studio which “uses natural language to build enterprise-grade applications“. In short, a low code tool using LLMs. They also offer an AI power assistant for various tasks called Amazon Q.
- GitHub Copilot, released in 2021, is now a well-established tool that helps developers code faster. It currently utilizes GPT-4 API calls.
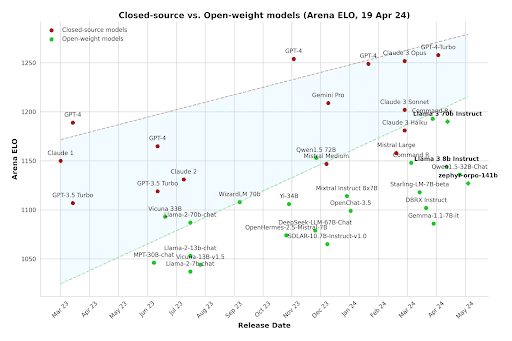
Open Source is Catching up to Speed
Follow us on LinkedIn to catch part 2 of this blog, where we will tell you what is coming in the future.