
Synthetic Imaging: A Revolution in the Making
Generative AI: A New Era in Image Creation

Posted by Guido Baez
on February 6, 2023 · 8 mins read
We'll talk about GPT again, won't we?
ChatGPT's debut revolutionized the AI industry. Its unparalleled dialogue skills allow for seamless conversation flow, addressing follow-up questions, correcting mistakes, challenging false assumptions, and declining inappropriate requests. Its responses are eerily human-like, making it a formidable adversary in passing the Turing test. What makes ChatGPT so captivating is its clever and intuitive chatting abilities. The service falls under the category of Generative AI, a type of model that can generate samples of a specific class.
And Generative AI isn't just about answering questions - it's a powerhouse of diverse capabilities, delivering outstanding results in areas such as (but not limited to):
- Text to 3D images (Dreamfusion, Magic3D)
- Images to text (Flamingo, VisualGPT)
- Text to video (Phenaki, Soundify)
- Text to audio (AudioLM, Whisper, Jukebox)
- Text to text (ChatGPT3, LaMDA, PEER, Speech From Brain)
- Text to code (Codex, Alphacode)
- Text to scientific texts (Galactica, Minerva)
In these tasks, the input of the models is text or images, but the output can be text, images, video, audio, code, and even scientific texts. This unlocks a realm of creativity and customization for individuals and businesses, streamlining both creative and non-creative tasks..
In this post, we will focus on Computer Vision, where there are a large library of models that can generate images. However, some questions arise:
- How realistic are the images produced by those models?
- How do they interact with the user? Is any input acceptable?
- Are images generated randomly, without user interaction?
- If a user can provide guidelines, in what ways can a user provide such a guideline?
- If a user wants to place a specific object in a new context within the picture, will that be doable?
Through a comprehensive analysis of Stable-Diffusion, we can answer all of these questions.
About Stable-Diffusion
Stable-Diffusion is a generative model that creates synthetic images. Initially, it could only generate images randomly. But with new architectures, images can be generated based on a set condition, like having a dog in the image.

In this figure we can see that, given a text input, the system provides random images following the guide provided by the texts. This type of generation is called text-to-image generation . There are also variants of this model that solve problems such as image-to-text, image-to-image, image-to-text-to-image generations.
How does it work?
To understand the functioning of Stable-Diffusion, we suggest examining its architecture. The design is based in an autoencoder, a model where the input is replicated in the output (The model compresses the input, and reconstructs from the compressed representation). Why is this relevant? because the image data is encoded and compressed, and the reconstruction is derived from the compression. The latent space, where the compressed information is stored, is an ideal location for modifications. By mastering the art of making changes in this space, we can generate random images that reflect our desired modifications.
This is the main principle in text-to-image used in Stable-Diffusion. Nevertheless, this principle does not rely on text only. As stated above, it can be modified to receive other inputs.
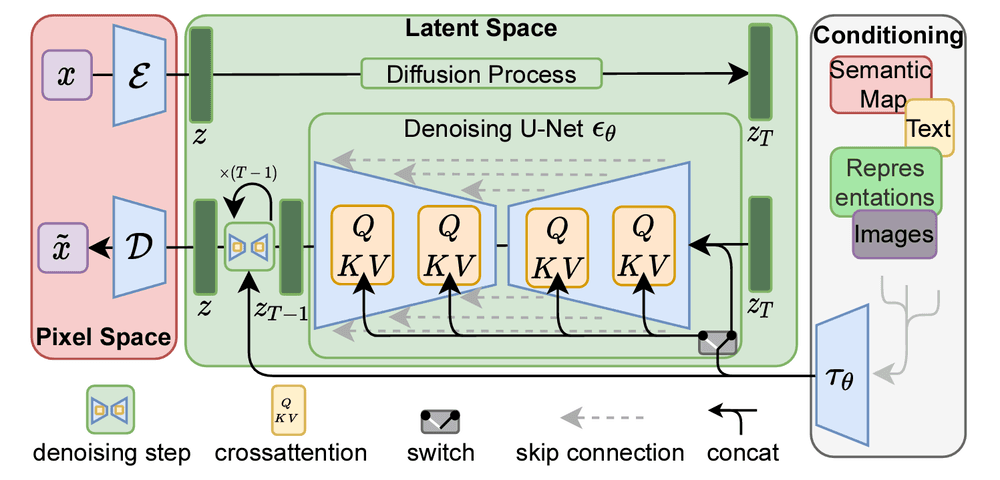
From the figure, we can see that the conditioning block is the one that handles possible applications by placing text, video, and anything that represents something that we are interested in converting into an image. The pixel space is where the input and output images lie. The latent space is where the compression occurs. The diffusion process is part of the encoding, and the denoising is part of the reconstruction, once the user requirement has been processed. More details can be found on this article.
Let's answer some of the questions presented in the introduction.
How good does it perform?

[One of the techniques derived from stable-diffusion is Dreambooth. Dreambooth trains a model using a small set of images of a particualr object of interest. A Stable-Diffusion model is fine-tuned to learn its features and details, and then it can be used to generate images of the object in situations and poses never seen by the user. In the figure, the object is the beagle dog. Once the model is trained, it can be used as the original model by passing text as inputs. In the figure, such inputs are "in the Acropolis", "in a doghouse", "swimming", "sleeping", "in a bucket", and "getting a haircut". Although the results are amazing, the human eye is good at detecting details like differences in the color tone or the dog's ears. Cue the tradeoff issue of fidelity vs. creativity. The model can't be creative while maintaining full fidelity to the original image. How realistic are these images? When asking these questions, we should consider how true they are to the original image, but also specific components like the consistency of brightness between the object and background, blurring, and the contact distance between a surface and the object.
Can you spot differences in the other pictures?
Applications

How can this model be used? There are many applications such as inpainting, when a part of an image is masked and replaced with another image. Variations of this method can be seen in this article, in Paint-by-example article, and Dreambooth. Some possible applications could be AI assisted visualization design, AI assisted advertising, AI sketch-to-concept, AI assisted image-edition, and so on...
How Can Generative AI Be Applied To Solve Today's Business Challenges
AI has proven succesful in solving problems in a wide variety of situations. For example, in the field of imaging, film industry and games use superresolution techniques for upsampling frames. With these, existing games can be played using 4k and even 8k resolution supported by current video cards. With so many articles available, and many more researchers and developers working hard on Stable-Diffusion, we are thinking about how we can take advantage of all the available tools to solve business problems. Some of those ideas are:
- Ad generation: Placing a specific object (e.g. an ad object such as the Mutt Data logo) in various settings with different variations. A simple example might be inpainting, but with more advanced technology, a designer could guide the system to draw logos in a variety of situations.

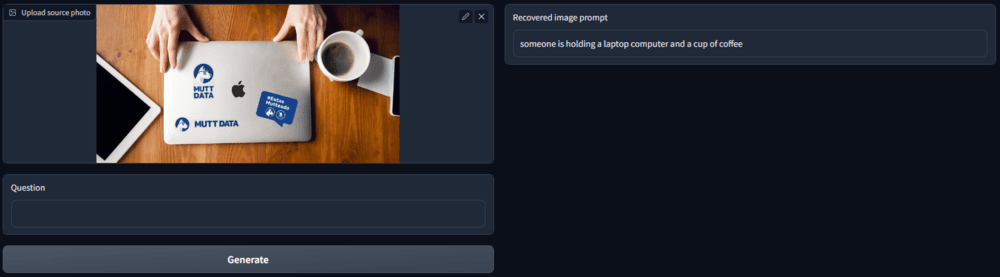
- Ad-to-Text: Where an advertisement is analyzed by a machine learning system and described in text form. This can provide insights into successful advertising elements such as popular colors, objects, and compositions. This information can be used to enhance advertising by capitalizing on current trends and working with advertising experts. An article on extracting text from images can be found here.
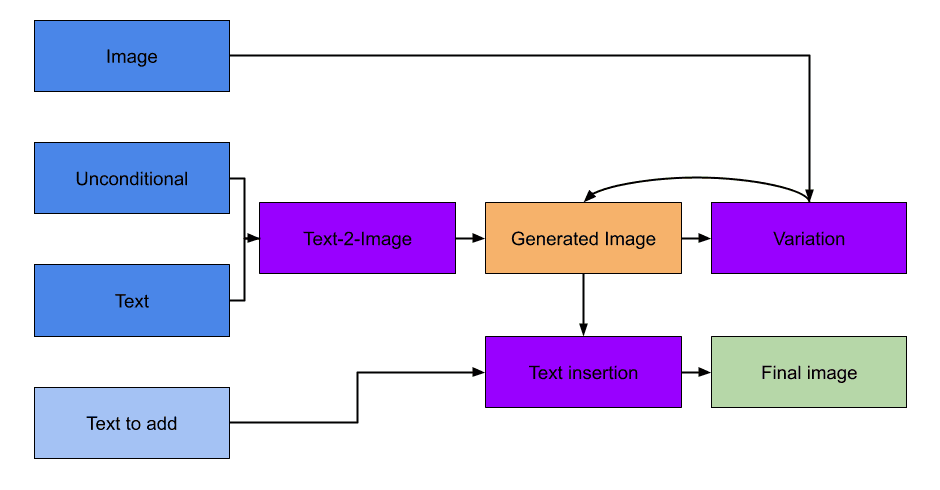
- Guided image composition: With the help of AI-assisted image generators, users can transform small human sketches or ideas into stunning images developed to the likes of the user. Some first steps for drafting are presented in this article. Mixing concepts are presented in this article.
Why is Ad-To-Text such a big deal? Imagine having the inside scoop on what works and what doesn't with specific customer groups. With Ad-To-Text marketing teams could efficiently tweak not just image descriptions but the intentions and underlying concepts behind ads. The best part? We believe that with the existing tools in the image-to-text field today it's possible to fine-tune models to learn this concepts from Ad datasets.
Drafting for guided image composition can be a time-consuming task, requiring multiple drafts before a final one is approved. Guided image composition could streamline this process by generating various ideas, creating rough sketches, and finishing the designer's vision. Creators save time to focus on the big picture and cut costs by using guided image composition. A system with these capabilities can be constructed using sketch generators, dual-guided models (which modify existing images with a specified text), and image variation tools.
Can you think of any other application for Stable-Diffusion?
Ethical considerations
Generative models have the potential to harness human imagination and generate even more creativity, or at the very least, support humans in unleashing their creativity. However, like many powerful tools, there are important ethical considerations to keep in mind. Generative AI has the potential to be misused in ways that have negative consequences, such as perpetuating socioeconomic bias, generating inappropriate images, facilitating harassment, and spreading misinformation. As its users, we have to be responsible and apply ethical principles, similar to when working with human visualization (more on visualization ethics here) The training process can have a significant impact on the ethics of the models. For example, this approach employs a reinforcement learning system that is trained with human input on what is deemed acceptable or not. It's crucial to keep in mind that no solution is foolproof as the training relies on the opinions and biases of a particular group.
Dive Deeper
This marks the end of the post, but not the end of the Generative AI story. Stable Diffusion is promising, but there are other techniques like IMAGEN and Muse worth exploring. Check out this review for a comprehensive look at the latest trends in Generative AI.