
Taking Your Modern Data Stack To The Next Level
How To Use Metadata Management To Make Your Data Useful

Posted by Mateo De Monasterio
on June 30, 2022 · 9 mins read
Jumping Right Back Into Modern Data Stacks
In our first blog entry on Modern Data Stack, we covered the main ingredients needed to build one. If you’ve gotten around to doing so, it’s safe to say you’ve got the compute and storage of huge amounts of data pretty much figured out. After all, they’re built on top of easily scalable cloud technologies.
Modern data stacks allow us to serve data from tons of different sources. And why not add more and more if the stack can handle it? Following that line of thought, adding more data sources means more users, each with their own unique use-case. What could possibly go wrong?
Users will eagerly jump in to solve their queries.
But they’ll face a harsh reality: they don’t even know where to start!
With tons of datasets to choose from, selecting the right source to query gets much harder.
Which table contains the data that can answer my question?
What does the cnt_entity_data column even mean?

Lucky users will find the right dataset or a willing person who’s been through the same troubles to help them. Filled with illusion they launch their queries. To their surprise, the results look weird: We sold negative one hundred cars last month? Mmm... Icky. When building stacks it’s common to focus on keeping data updated all the time. But what about checking what's actually being added? More often than not, users will find a column has been filled with null values for days, messing up key business metrics and KPIs. If only there was a way to keep our data clean...
Imagine for a minute, it’s your data stack. To make matters worse, on top of all the mentioned challenges: you’ve got mail. It's your unhappy boss... A huge amount of sensitive information has been leaked. Seems like letting all of our users access all data wasn’t a great idea...
All these issues are possible indicators of a common problem: building a scalable data stack incredibly fast but failing to make that stack useful for the users. Today's post will introduce Data Discovery, Data Observability and Data Governance. These concepts may help you avoid some of the common pitfalls of building a modern data stack. Then we’ll see how they come together in Data Catalog tools, which are powered by metadata: data about data.
Data Discoverability: Can I find the right Data?
What good is having tons of data if users can't find it or don't know how to use it. Just like a library keeps books tagged, sorted and easy to find, the same can be done for data.
This is what Data Discoverability is all about: tagging data so that users can easily understand and find it. Being able to add an explanation to a column and tag tables in order to do a quick search to filter our data by topic and source. Moreover, it's also possible to check which users use specific data the most. It's always a good idea to know the experts who can help us in a jam!
However, Data Discoverability is not just about data. Queries, dashboards and discussions are also important assets. By storing these assets and making them easy to find, it's possible to reuse work done by teammates.
With Data Discoverability users can now find the right data, and the owners of that data can check the top queries and most used columns.

Data Observability: Can I Trust My Data?
Can you trust your data? Is your data healthy? Is it usable? Is it safe to act upon? These are some of the questions Data Observability answers.
In short, Data Observability refers to best practices applied to understand if the data inputted to systems is healthy. The main objective? Uncovering issues before they have negative impacts on the people using that data.
And it’s not simply about finding out if data can be trusted, it’s about doing so in real-time. One of the ideas behind data observability is to analyse the health of data and its flow in order to discover issues before the data is actually needed, fixing said issues in an efficient and timely manner.
So why is this relevant? The fact of the matter is that bad data can have high costs. Misinformed decisions or long periods of time where data is just not working (also known as downtime) may impact negatively on data-driven organisations. A number of issues can arise from inaccurate, erroneous or even missing data.
Either way, Data Observability can aid businesses in keeping their modern data stack flowing without hiccups by improving the quality of data and preventing issues by discovering problems in time. As a result, the credibility of data and data teams will increase inside the organisation. We were talking about Modern Data Stack though, right? So how does Data Observability connect to the post’s main topic?
Data observability plays a key role in the smooth functioning of a company’s modern data stack. You may have chosen all the right tools and best practices but if they’re not properly integrated and the oil going in isn’t high quality and easily flowing then the stack won’t deliver the desired results.
Data Governance: How is my Data being managed?
At the end of the day, data is produced, consumed and used by people. For each dataset it's important to understand which team is its owner, who has read and who has write access, and what each term used alongside the data means. This is what Data Governance is all about: manage your data and avoid chaos.
Processes should be clear: Who do I have to ask permission for to access a certain asset? If there is no clear process to do this, a person might get unnecessarily blocked for a long period of time.
Data Governance should add visibility to your system: Who is running that incredibly compute-intensive query? Are they doing it maliciously, or do they mean no harm?
And there is no knowing what we will be able to do with data as technology continues to progress. In our imaginations, the sky's the limit. In the real world, we need privacy regulations and guidelines. Such examples might be the GDPR and CCPA. To face compliance and anti-abuse concerns, teams need to implement fine-grained control of policies regarding data access and storage.
Only some users need to access sensitive information for their day-to-day activities. Most users only need a subset of data. For this reason, assigning specific roles and permissions to different users is key to achieving adequate governance over data.
The Solution: Time To Get a Data Catalog!
We never said data was simple. So, we want data we can trust, we can validate, and govern. We need a solution that allows for management, tracking, and understanding of data. The answer? Well... more data of course.
In the past few years, there has been a rise in tools that can solve these issues: the Data Catalog. Think of them as a way to better organise your data. They're are powered by metadata: data about data.
Picture a table containing the results of a Machine Learning experiment over time. There is more information in this table than what you can see in its rows. Which dataset or services were used as an input for your experiment? Which team is in charge of this Machine Learning system? Was the last run executed programmatically or manually? Who is consuming this table?

Metadata is everywhere, a document, a Slack channel, even in our thoughts. It just needs to be inserted into a real scalable and resilient system. Remember: metadata is still data. That means that all the techniques we know for storing data still apply to metadata!
All Data Catalog tools need a place to store your metadata (usually a relational database). To ingest your metadata, you’ll have to push it through an API or stream. Worst case scenario, you’ll have to crawl your source to get your metadata into your catalog.
Now that you know how a Data Catalog works, we can introduce our favorite: DataHub.
Enter DataHub
DataHub is a 3rd-generation Data Catalog that enables data discovery, observability, and governance over a company’s data ecosystem. It was open-sourced by Linkedin 3 years ago and used internally for a few more years.
It can be connected to several systems (databases, data warehouses, ML feature stores, dashboards with charts) to keep track of assets and their metadata changes (new models, updates in existing models, etc.). It’s capable of integrating with other popular data tools like Apache Airflow or dbt via connectors, so it’s easy to get started.
We’ve found it to be a robust tool that covers most use cases around metadata management. Don’t believe us? You can try DataHub out yourself from your browser!
Here's how DataHub fares against some of the previously mentioned issues:
Data Discovery: search and understand through metadata
Metadata allows us to add tags about our dataset and comments to our fields. DataHub's front page comes with a search bar that allows users to search for datasets, people, and other assets.
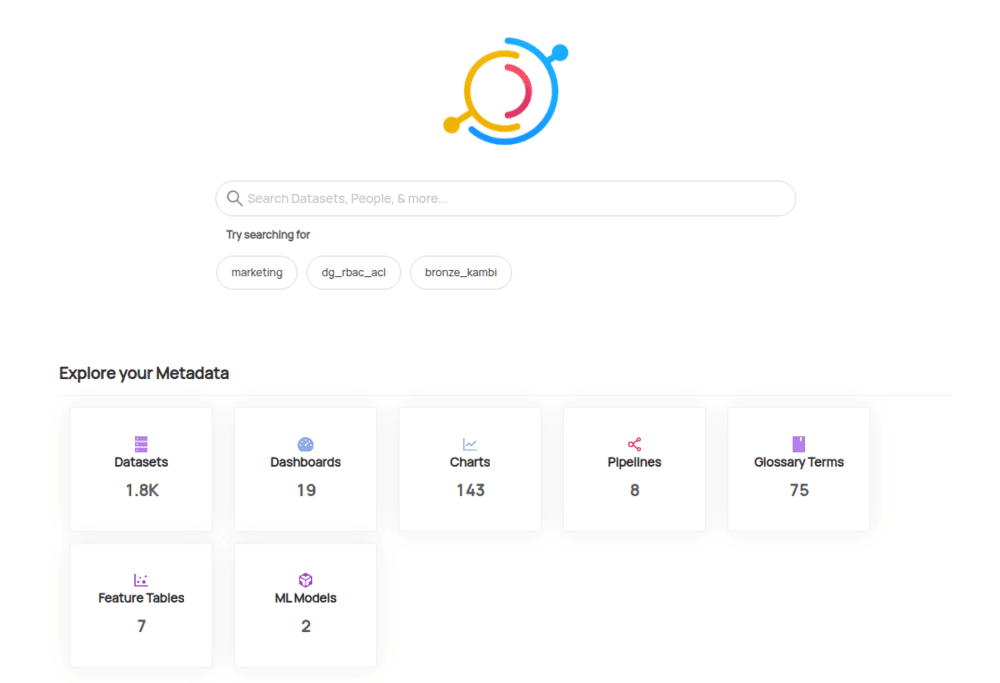
From getting the correct dataset for your query to understanding how KPIs are calculated, it's all metadata.
Data Observation: understand your data lineage
DataHub offers lineage visualization. Many data products consume data from different sources, and in turn, these sources consume even more data sources. Visualizing the data lineage allows teams to analyze the impact of potential changes in data. Furthermore, it comes in handy for debugging: a team can simply check their lineage from end to end to find the cause of the bag and who might have accidentally inserted it.

Data Governance: know who is in charge of what
DataHub versions metadata by default. Essentially, this means that when changes are made, the old version of that metadata is stored. This is great because it's possible to audit a system: if a user got their permissions changed, even for a moment, it's detectable.
Thanks to metadata tags and its glossary its easy to set clear meaning to data, define who is reponsible for what and set clear proceses to access.
Who Does MetaData Management Benefit?
MetaData management benefits the whole organization:
- Data Consumers: they’ll be able to reach the data they need, understand the ecosystem around it and even learn about dashboards or queries someone else made that otherwise they wouldn’t have heard of.
- Data Producers: they’ll be able to understand their users. What is the most popular query? Which teams are using my data and how?.
- Organisation leaders: Data Catalogs give you the big picture. With just a look they’ll be able to understand the flow of data between teams, who is responsible for what asset and their privacy levels.
Some alternatives to DataHub
DataHub is just one of the awesome Data Catalog tools available. Some others we've enjoyed using are:
- OpenMetadata: this is an incredibly powerful tool thanks to its connectors to other popular sources like Postgres, Snowflake and Redshift. It's also incredibly easy to customize or add support for any service.
- Amundsen: Amundsen might fall behind on lineage visualization, but its search functionality is top-notch: it uses a Page-Rank like algorithm to organize search results, and the most used queries, datasets and assets appear first. Think of it as Google but for data!
- OpenLineage: it might not be as easy to setup OpenLineage, but it sure is worth it. It has tons of connectors to other data tools like Airflow, dbt, Great Expectations, Iceberg, Pandas, Spark and Data Catalog tools like DataHub and Amundsen!
Challenges of Metadata Management
We hope we've convinced you of the incredible use of metadata management. However, it's not without its challenges:
First off, it's important to review your metadata case-by-case to decide how to structure it. For example, you might decide to use a few common fields between all datasets. In the long run, this could be incredibly limiting. Each dataset has useful metadata to bring to the table.
Picture doing the opposite. Using a key-value structure might not be the best idea either. You can forget about being able to validate your structure this way! The point of these examples is the same: it's important to analyse the correct structure on a case-to-case basis.
Good infrastructure and proper maintenance will always go a long way.
You’ll have to decide for each data source whether to use the Kafka stream or to use the API, and which is the best way to do either of those.
Presently, stream technologies are mature and reliable but it's not a trivial task to set up a stream infrastructure from the ground up.
At Mutt Data, we've worked on tons of different projects, each with its own business needs and infrastructure. We understand how to work with different data systems and how to build great infrastructures around them. Want to boost your business with data? Need help building your metadata management system? Hit us up!
Wrapping Up
Mutt Data can help you crystallize your data strategy through the design and implementation of technical capabilities and best practices. We study your company’s business goals to understand what has to change so we can help you accomplish it through a robust technical strategy with a clear roadmap and set of milestones. Talk to one of our sales reps at hi@muttdata.ai or check out our sales booklet and blog.
Explore our client results through our success stories or see our Clutch profile for client reviews.
Resources
- Das, Shirshanka. "DataHub: Popular metadata architectures explained." Linkedin Engineering, URL.
- "What is Metadata Management?" Claravine, URL.
- OpenMetadata's website.
- Amundsen's website.
- OpenLineage's website.