
SoaM Public Release
The easiest way to build and run your time-series forecasting pipelines.

Posted by Eugenio Scafati
on September 15, 2021 · 7 mins read
What is SoaM?
SoaM is a library designed by Mutt. Its goal is to provide a "batteries included" framework for forecasting and anomaly detection pipelines. SoaM stems from multiple project experiences, hence the name: Son of a Mutt = SoaM.
We developed this library because we encountered the need for a strong and clear framework for forecasting projects and we didn’t find an open-source solution that fitted all of our needs. As Mutters, one of our core values is being Data Nerds, upon this: we are always seeking ways to optimize our time and productivity when working with data. By developing SoaM, the same design and code could be reused on different projects when needed.
SoaM stands out from other solutions by providing an end-to-end framework for forecasting and anomaly detection products. From the extraction of the data to the reporting of the results. At every stage, SoaM provides plug-and-play components that will help you reduce development time.

The beginnings and the road to this public release
This long road started back on the 21st of April 2020 when a couple of Mutters had the bright idea to start developing this library and merged the first version of SoaM.
Since then, we have continually pivoted and iterated on the scope of the project but the main goal was always the same: to be the best open-source framework for time-series forecasting data products.
How we managed to build it
We built this project by setting ambitious goals for each Sprint and dividing the workload among the Mutters involved. We usually meet twice a week. Fridays are for planning and catchup and Mondays are for live coding. During the week, our priority is always set on external projects, but from time to time, we find some periods we can dedicate to contribute and commit some code to this library.
We also incentivize new Mutters to solve issues during their onboarding period so they can learn about our working methodologies and schemes in a safe environment and most importantly: meet new colleagues!
Main Features
We can understand SoaM by breaking it down into four main features where each of them represents a stage in a forecasting pipeline. We divide each stage into different conceptual steps, and we use Prefect tasks and flows to help us build these data pipelines.
1. Extraction
This module will assist you with the extraction and the aggregation of your data from any given SQL data source and provide you with a pandas DataFrame for easy manipulation.
2. Pre-processing
Once your data is loaded, SoaM provides you with out-of-the-box tools to perform preprocessing tasks such as any Scikit-Learn transformation --like the Min-Max Scaler-- or even custom ones. Additionally, you can merge, concat, and slice your loaded pandas DataFrame with our built-in modules.
3. Forecasting
Since SoaM is intended for time-series forecasting, we have already built-in forecasting methods such as Statsmodel's Exponential Smoothing and SARIMAX, Uber's Orbit, and Facebook's Prophet for you to easily fit and compare models performance. Of course, we don't limit the usability just to these models, you can always import your preferred forecasting algorithms as well.
4. Post-processing
After you forecast for future periods, you might want to persist the results somewhere, to detect anomalies, backtest your experiments, plot your results, and even report them by email or slack to your colleagues.
Well... we understand this might be a lot to cover. The good news is SoaM will also help you fulfill these tasks in a blink of an eye.
Simple end-to-end code example
This is how a simple and generic use case of SoaM would look like:
# 1. Extraction # Extractor object initialization with the db client and the table name given. from soam.workflow.time_series_extractor import TimeSeriesExtractor extractor = TimeSeriesExtractor(db=db_client, table_name='table_name') # 2. Pre-processing # Transformer object initialization with a chosen Scikit-Learn transformation. from soam.workflow import Transformer from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() transformer = Transformer(transformer = scaler) # The add_future_dates method refers to the amount of periods we will later predict, # we create a prefect task for this job. from soam.utilities.utils import add_future_dates from prefect import task @task() def add_future_dates(df: pd.DataFrame): df = add_future_dates(df, periods=periods, frequency="d") return df # 3. Forecasting # Forecaster object initialization with the output_length equal to the amount # of periods we will predict. from soam.models.prophet import SkProphet from soam.workflow.forecaster import Forecaster my_model = SkProphet() forecaster = Forecaster(my_model, output_length=periods) # 4. Post-processing # Generate a plot and send it by email. # 4a. SOAM ForecastPlotterTask object initialization. from soam.plotting.forecast_plotter import ForecastPlotterTask from soam.constants import PLOT_CONFIG from copy import deepcopy from pathlib import Path plot_config = deepcopy(PLOT_CONFIG) forecast_plotter = ForecastPlotterTask( path = Path('img_path'), metric_name = "metric_name", plot_config = plot_config ) # 4b. SOAM Mail Report object initialization. from soam.reporting.mail_report import MailReportTask mail_report = MailReportTask( mail_recipients_list = ["mail@muttdata.ai"], metric_name = "metric_name" ) # 5. SoaMFlow # Using SoamFlow to run everything as a prefect pipeline. from soam.core import SoamFlow with SoamFlow(name = "flow") as flow: # EXTRACTION df = extractor(build_query_kwargs = query_dict) # PRE PROCESSING df['column_name'] = transformer(df['column_name']) df = add_future_dates(df = df) # FORECASTING predictions, time_series, model = forecaster(time_series=df) # PLOTTING forecast_plotter(time_series, predictions) # REPORTING mail_report(current_date = "current_date", plot_filename = 'img_path.png') # Execute the pipeline flow.run() # Voilà! # Now check your inbox and you should find an email that looks like the following:
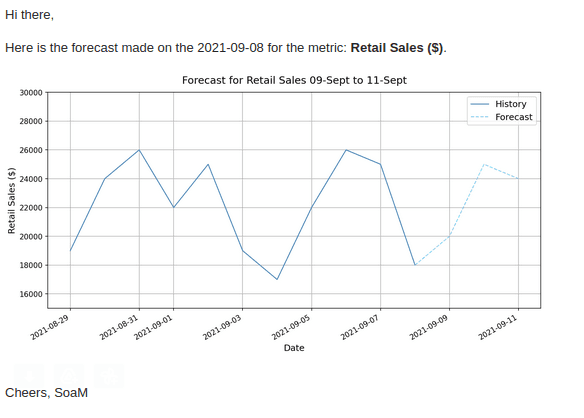
How are we using it today?
Of course, SoaM is present in lots of our projects. A common use case would be to easily bootstrap an anomaly detection pipeline for monitoring time-series data. In one of such instances, we needed to quickly spin up a pipeline to detect anomalous values on business KPIs as part of the implementation of a DataOps Platform to improve data pipeline creation and management across the whole organization. For this, we leveraged SoaM modules to extract time-series data from Amazon Redshift, train a model on the data, detect anomalies, plot the results, and send a report to a Slack channel. We successfully got this pipeline up and running with minimal custom code, just adding custom plot logic for styling purposes (copy and paste it from your Jupyter Notebook!).
This way SoaM significantly reduces our workload and structures our code the Mutt way. In the image below you can see how we receive this report on our Slack Channel. We scheduled this pipeline to run daily with Apache Airflow and got positive results by enabling the client to make data-driven decisions with the minimal development effort.


In another case we needed to detect and report significant drifts on the input data of an automated ad budget allocator, this helped us to reduce losses by adjusting the allocator's parameters on volatile periods.
Getting started
Have we caught your attention yet? Ready to start using SoaM? Relax... we've got you covered. Mutters understand the importance of clean and precise documentation, and SoaM was no exception.
First, you can take a peek at our Sphinx docs to have an overview of the project.
Anyways, if you made it this far you're probably craving for some code, if that's the case we have some fresh Jupyter Notebooks with examples such as our Quickstart I and our Quickstart II where we take you for a ride on how to leverage SoaM tools effectively.
That's not all, you might be wondering how an end-to-end product using SoaM will look like? How to integrate it with other tools such as Apache Airflow? Well... we also have documentation for that. Check our End to End data product with SoaM post to see how that will look like.
How can you use it?
You can install it directly from PyPI with a simple: pip install soam.
Check the installation section on our README for further information on installation and available extras.
How we maintain a clean and scalable codebase
While developing SoaM we applied efficient practices to ensure code quality and robust deployments. This helps us guarantee a baseline of code quality and automate the deployment process. By these we mean:
- Running tests on the code with the
pytestframework. - Updating the
CHANGELOGfile. - Versioning the code with semantic versioning standards.
- Configuring pre-commit hooks and code linting such as
black,pylint,mypy, and others. - Documenting the code and running
docstringcontrols to ensure a minimum percentage of docstrings coverage. - Code review between peers (you are not able to merge unless a colleague has approved your request).
- Deploying the new version to PyPI or GitLab registry.

One of our core values at Mutt is that we are an Open Team. We all make mistakes and need help fixing them. We foster psychological safety. When we don't know something we ask for advice.
We expect everyone contributing to SoaM to follow this principle. Be kind, don’t be rude, keep it friendly; learn, teach, ask and help.
Please don't hesitate to contribute to our library in case you feel like it, we encourage you to do so. Check our Contributing Guidelines to see how to make useful contributions.
Next Steps
Regarding plans and possible future releases, some of the things we have in our scope contemplate:
- Evangelize SoaM internally and externally. We want developers to start using SoaM!
- Implement pre-built anomaly detection reports.
- Migrate package setup to
Poetry. Check our blogpost on Why Should You Use Poetry to Manage Python Dependencies. - Homogenize constructor methods for models.
- Migrate utility functions to
muttlib.Muttlibis our utils library, check our blogpost on Muttlib Public Release.
Our Team
There is a lot of hard work behind this library and a big team responsible for it. We acknowledge the effort of all the data nerds behind this development:
- Alejandro Rusi
- Diego Leguizamón
- Diego Lizondo
- Eugenio Scafati
- Fabian Wolfmann
- Federico Font
- Francisco Lopez Destain
- Guido Trucco
- Hugo Daniel Viotti
- Juan Martin Pampliega
- Pablo Andres Lorenzatto
- Wenceslao Villegas
It has been a great experience to build SoaM together as a team and we are super proud of the result.
Thanks to all of them!