
6 Ways you can use machine learning to take your marketing efforts to the next level
When machine learning meets modern marketing

Posted by Juan Martin Pampliega
on July 16, 2021 · 13 mins read
Machine Learning Meets Marketing
As data science continues to mature, many businesses look to machine learning to solve their problems. In one form or another most businesses today are data businesses or at least data based. Data is everywhere and with the right tools it’s a goldmine capable of generating actionable insights and competitive advantages.
Our broad experience building ad tech platforms and optimizing marketing for large marketplaces and gaming companies among others showed us that digital marketing is no exception. Presently marketing decisions can be automated and directed by behavioral client data limiting the impact of human biases implicit in traditional methods.
In this post we will describe six machine learning techniques and explain how they can be combined with each other to form an automated marketing pipeline.
1. Customer Lifetime Value (CLTV)
What’s the expected value of a client after a certain amount of time? A customer’s Lifetime Value represents the revenue a company can expect a user to generate in their lifetime (provider-client relationship).
Why is this important? Generating insights regarding expected revenue may lead to improved marketing investments in acquisition, retention and engagement efforts. In short, LTV is useful for measuring the extent to which marketers' efforts are delivering positive return on investments.
Also, initial information can be misleading. A customer who made one very expensive purchase could potentially be less valuable than another customer who continually makes small purchases over a long period of time.
How do we calculate ROI using CLTV?
ROI = Customer Lifetime Value / Acquisition Investment
CLTV allows marketers to answer some of the following questions:
- Which customer is more valuable?
- Which customer’s should I focus resources and attention on?
- Which channel is generating the most valuable customers?
When trying to answer these questions, it is common to model the lifetime value for a defined period of time, one month, three months or maybe one year. To do so, at least a week or two of user behavioral data is required.
CLTV Models
We can group CLTV models into two broad groups: Probabilistic models and Machine Learning models or better yet traditional models and Machine Learning models.
In the first case, models are based on previous purchase behaviour of customers. The main input is how recently customers have purchased, how often they have purchased and how much money they have destined to said purchases on average. This is also known as Recency, Frequency and Monetary Value or RFM. These models are based purely on historical transaction data.
ML models, on the other hand, are not limited to purchase driven data. They use a broader context data set with information regarding the users engagement, session behaviour, social media use as well as device type, purchase habits, etc which allow for deeper insights. Algorithms use this data to predict which behaviours commonly relate to user value and then assign a value to new users by combining these predictions with the users specific attributes (session interactions, age, country, platform of choice, etc).
Instead of simply understanding what has been previously bought and how, ML allows for deep insight into who the customer is, creating customer types with a better shot at modelling their behaviour in the future.
A probabilistic approach may be more appropriate if you have limited access to context data or if the data set you’re working with is limited. On the other hand ML models are a good fit when you have access to large data sets and context data.

CLTV should be compared with Customer Acquisition Cost (CAC) to make sure that the company is investing in the appropriate customer acquisition strategies.
2. Customer Churn Prediction
How likely is it that a customer will stop using a service, unsubscribe or stop purchasing a product? Depending on the industry, the question might differ slightly but the concept is the same: when are we about to lose a customer? Customer churn prediction looks to answer this question.

So, why is churn so important? In short, the cost of acquiring new customers compared to that of retaining them can be up to five times more expensive. What’s more, increasing customer retention rates by as little as five percent can lead to profits increasing over twenty-five percent. Additionally, returning customers are likely to spend sixty-seven percent more on your company’s products.
Statistics aside, the bottom line is: Acquiring new clients is key, but retaining existing clients offers a better return on investment over limited resources.
The key is to identify customers who are about to churn and give them enough incentives to come back, or better yet stop them from leaving in the first place. Dedicated campaigns tailored for each customer segment on their preferred channels are required to reactivate these customers. This is where machine learning comes in.
We can group churn into two types, voluntary and involuntary. Voluntary churn occurs when a customer consciously decides to change provider due to cost or unsatisfaction with a service or product. Involuntary churn occurs due to reasons unrelated to your business quality or cost such as a client moving away from the country where the service is provided or a credit card being declined.
We can also differentiate between churn in contract services and non-contract services. In a non-contract scenario a customer is free to purchase or not at any given time, the clearest example being the retail industry. However, in the case of contract services the customer signs a contract where he pays recurrently in exchange for a service that will be delivered over time. An example of this would be a subscription service.
Why are these two differentiations important? The concrete actions to take to reduce voluntary churn are different then those for involuntary churn. In the first case you might consider asking for customer feedback, adding commonly desired features, offering incentives or improving tutorials or documentation for your product or service. In the latter, you could regularly monitor customer credit cards to make sure information is up to date (avoid declined cards) or email the client for debt collection before cancelling a subscription among others.
In terms of contract and no contract service, the same applies. Different concrete actions can be taken depending on the type of service. For example, payment failures will most likely be an issue to address in contract services.
Hooked on churn? Here’s a recommended paper on imbalanced data, what it is, how it can be troublesome for churn prediction and how to handle it.
Along with segmentation and identifying the Life Time Value (LTV) of the customer, campaigns should be geared towards high valued customers who are about to churn rather than the customers with low LTV.
3. Automatic Recommendation
What products should we offer to our clients? What are the most likely opportunities we can offer for cross-selling or up-selling?
With access to hundreds of thousands if not millions of products and services online marketplaces and stores have made endless amounts of content available to clients. So, how do we identify what a client might like? How do we capitalize on selling opportunities?
Recommendation engines are used to identify which items or services might be to be consumed together. Using recommendation algorithms, these systems analyze data about items, products and services that customers have bought, liked or subscribed to in the past with the premise that the same people might be interested in those products in the future based on their tastes.
This data together with data about products liked or purchased by similar customers allows recommendation engines to generate accurate suggestions and identify opportunities for up-selling and cross-selling.
Amazon pioneered this concept in retail using web/mobile usage history and customer product rating data sets. It’s since then spread to countless businesses. Think “Recommended Videos” on YouTube, “Jobs You May Be Interested In” on LinkedIn or even “People You May Know” on Facebook.
Other well-known examples of successful use of recommendation systems come from the likes of Netflix and Spotify. The music streaming service claimed that their recommendation algorithm was key to increasing their monthly users from 75 million to 100 million. Also in the streaming business, Netflix is said to save up to one billion dollars annually thanks to their recommendation system. Additionally, according to McKinsey around 75% of title selections on Netflix come from their recommendation systems.
The main recommendation systems fall into two categories: Collaborative Filtering and Content Based Filtering although both methods can also be combined into a more comprehensive solution.
Collaborative Filtering
Collaborative filtering (Similar to Amazon's Customers who purchased this also purchased that) — The collaborative filtering is based on the premise that customers with similar characteristics purchase similar products. In short, the system will recommend products that other users, who have similar behaviours and interests have bought. The assumption being that if you’ve liked similar product in the past you should like similar products in the future.

As interests and behaviours change the system adapts to these changes, keeping recommendations relevant. However, it does require new users to interact for a period of time to be able to recommend products accurately.
Content Filtering
Content-based filtering studies the products that the customer has bought in the past to create the profile of the customer. It then recommends similar products to those the user has purchased or liked in the past.

Similarly to collaborative filtering the recommendation systems will adapt to changes in the users likes and dislikes. Currently, many people opt for hybrid methods that combine collaborative and content filtering.
4. Customer Segmentation
How should we generate customer groups? Traditionally marketers relied on the spray and pray approach to marketing. Segmentation was based on demographic characteristics with little specificity.
However, today data is abundant, and when properly processed it represents a segmentation goldmine. By leveraging cross channel usage data, contextual information and real-time activity for each shopper, true personalization and clear segmentation is achieved.
So, why is it important? Segmentation aids marketers in finding big spenders, loyal spenders and hibernating customers. Once again, with a clear understanding of our customers and the correct machine learning techniques we can achieve an efficient use of limited resources.
Segmentation coupled with Customer Life Time Value (CLTV) and churn prediction allows marketers to identify groups of users based on their estimated value rather than demographic characteristics. These groups can be used to decide specific actions to be applied:
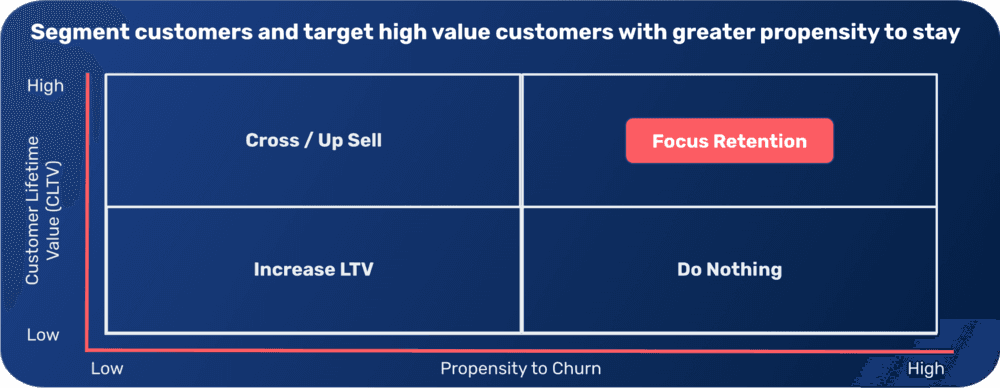
5. Multichannel Ad Budget Optimization
Am I distributing my advertising budget optimally among different channels?
Marketers are often responsible for achieving demanding growth goals with limited budgets. So much so, growth-hacking has become a commonplace marketing technique globally. The essence being to generate as much growth as possible using the least resources: A lot with little.
Some of the previously mentioned tools help with ROI and efficient budget allocation, but they’re only one part of it. It’s not only about deciding how much to invest and on what customers but also how to do so: this means analyzing not only segments, churn and LTV but also channels and the activities and parameters that relate to each one.
Marketing teams usually use multiple channels - such as sponsored search, display ads, and emails - to reach their customers, and each channel usually includes multiple parameters associated with different costs.

The variety of channels leads to the problem of marketing spend optimization, which requires estimating the true contribution of individual channels and activities to the final outcome and optimally allocating budgets across these channels, or even setting individual activity parameters such as bids in sponsored keyword search.
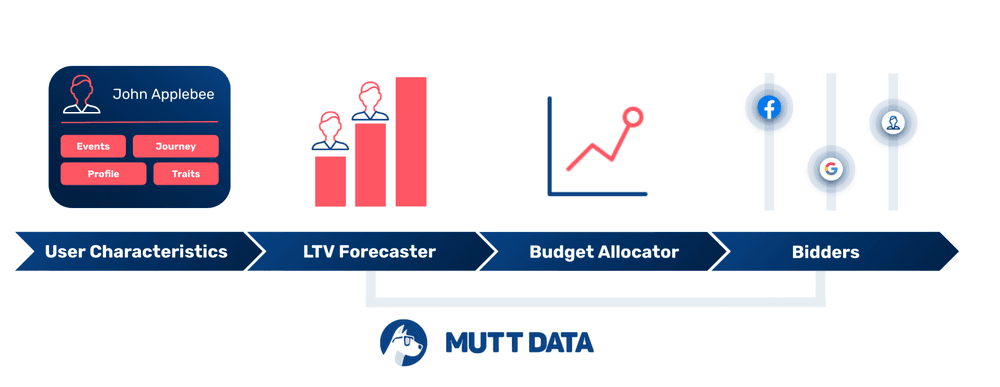
Using machine learning it's possible to run multi-channel campaigns and optimize their budget based on real-time performance data.
In this way multiple campaigns can be run at the same time in Facebook, Google, Instagram or any other set of channels while the total available budget will be automatically distributed between them seeking to maximize ROI or incremental revenue with a ROI constraint.
6. Attribution
Which marketing actions generated a given action by the client? According to a report published by Salesforce an average consumer can use up to ten different channels to reach a product. With customer journeys this fragmented, marketers have to use multi-channel strategies, but which channel is generating conversions?
Attribution enables marketers to identify the channel and specific action that generated a conversion.

Why is this important? By understanding each channel’s contribution to conversions, you can consequently adjust budgets to maximize ROI. Additionally, customer attribution sheds light on customer journeys. Attribution can reveal high engagement touchpoints, facilitate making decisions about specific channels as well as defining buyer personas and improving segmentation.
There are different attribution models, ranging from simple ones to complex ones. Marketers should look at the appropriate attribution model based on the use case and industry. Here’s a quick summary of the main models, their pros and cons:
Last Click Attribution
This is the most common model, where all the credit for the conversion is attributed to the last touchpoint in the customer’s journey. The positive aspect of this model is it’s simplicity, also some might argue it’s crediting the final driver for the purchase. However, it may be deceptive, it ignores the whole of the customer journey.

First Click Attribution
In the opposite case, all the credit for the conversion is attributed to the first touchpoint in the customer’s journey. The positive aspect is also its simplicity and finding out how people are discovering your product/service. On the other hand, it’s inaccurate and ignores most of the customer’s journey.

Linear Attribution
In this model each touchpoint in the customer’s journey is attributed equal credit for the sale or conversion of said customer. The big advantage is that marketers get a full picture of the customer’s journey.
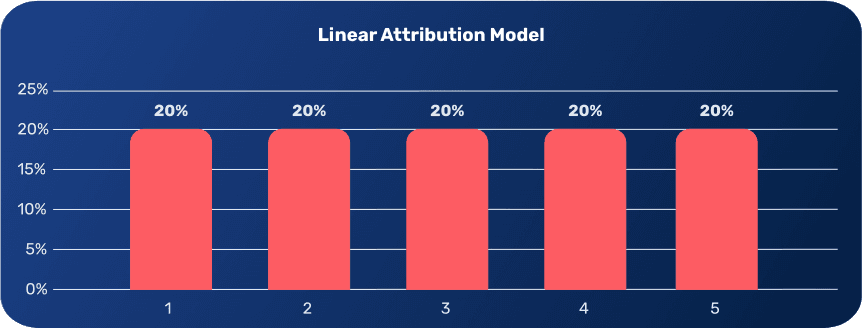
Where’s the catch? Although linear attribution is a step in the right direction as it takes into account multiple touchpoints or channels it represents a medal for participation scenario. It lacks deeper insight, by assigning equal credit to all touches optimization opportunities are lost for the channels that generate greater impact.
The data regarding ROI is flawed: Imagine we’re a user online, we come across an ad for a product on Facebook, because of this ad we decide to visit the brand’s website but on second thought leave without purchasing anything. A few days later, we see a different ad (another channel) whilst reading the news online. We visit the brand’s site for a second time, this time around we’re hooked and buy the product.
The problem is, Facebook will take credit for this conversion because the purchase occurred in a certain window of time. The second channel will also take credit for the conversion. The end result is an inaccurate ROI. Instead of assigning a certain percentage to each platform, each platform credits itself for 100% of the purchase.
Time Decay Attribution Model
This model factors in time. In a similar scenario where a customer goes through different touchpoints until a sale is achieved, this model analyzes which of these touchpoints is closest in time to the sale or conversion. The touchpoint visited closest to the sale will be attributed the most credit.
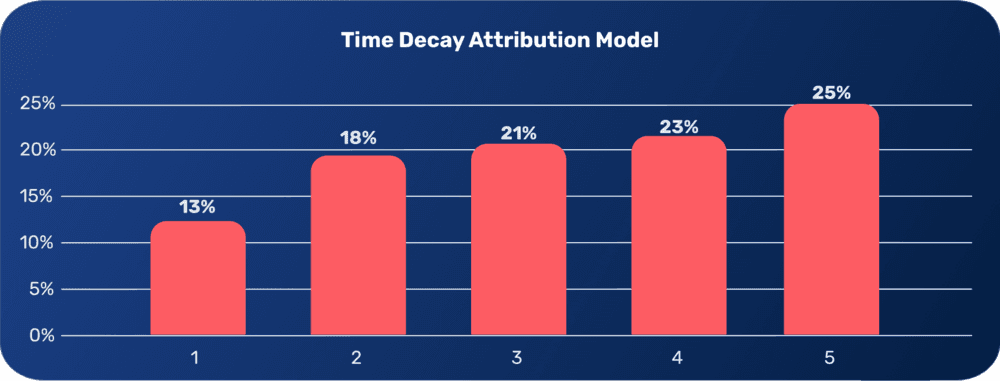
Unlike linear modelling, this model takes into account that different touchpoints generate different impacts on the road to a conversion. However, the first touchpoint, which might have been the customer’s first interaction with a brand may be ignored.
Position Attribution Model
We could consider this model to be a hybrid of the two previous models. In short, it assigns 40% to the first touchpoint and 40% to the last touchpoint with the remaining credit attributed linearly to all the touchpoints in between.
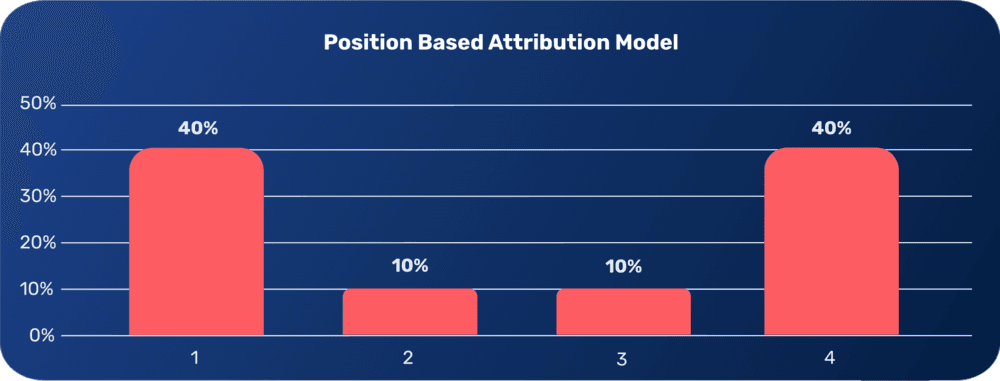
The positive aspect of this model is that it takes all touchpoints into consideration like the linear approach but still applies an impact differentiation like the time decay model does. However, by using this model the middle touchpoints could be undervalued.
Data Driven Attribution Model
Data Driven models are based on a concept from cooperative game theory called Shapley Value. The simple explanation? Lloyd Shapley, an economics Nobel, found a way to distribute the output of a team, fairly, among its members based on each member's marginal contribution to the total output.
If we think about marketing, we can consider the different touchpoints in a customer journey to be the different team members and the impact of each point to be their marginal contribution. We have an output which is the conversion and we want to fairly attribute it to the different touchpoints.
In contrast, with traditional models, data driven models use machine learning to generate custom models unique to each advertiser. In other words, this is not a predefined, deterministic, rule-based model.
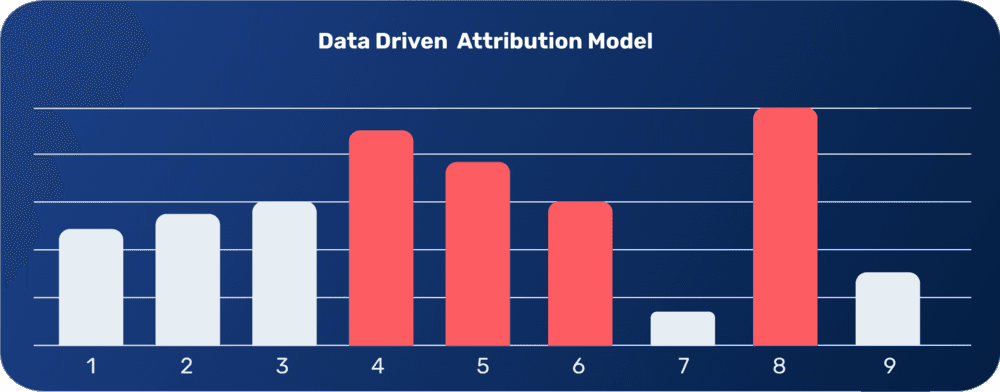
The data driven approach focuses on conversion data. The model will search for patterns in all the different possible combinations of touchpoints when comparing customer journey’s of customers who converted and customer journeys of customers who didn’t convert. The end result is a better understanding of which ads have more impact on conversion goals.
Completing The Puzzle
Although each of the previously mentioned tasks can generate business value by themselves it’s possible to combine them into one data driven marketing pipeline. This might look something like this:

The interactions seen between components in this diagram, can be summarised as following:
- An attribution model can be used to estimate which marketing action or actions are responsible for the conversion. Depending on the case this can be used in turn to estimate CVR, CTR or ROI of the interaction.
- The LTV and churn prediction models provide variables that can be used to segment users and decide further actions based on their expected results.
- Once the users are segmented a recommendation engine can be used to suggest specific actions for each user depending on the group they belong.
- The groups generated by the segmentation model, a set of recommended offers to define marketing campaigns and the estimation of the effectiveness of each marketing action can be used in conjunction with an optimization algorithm to allocate the available ad budget in the optimal way to increase ROI.
Wrapping Up
We hope you’ve found this post useful, and at least mildly entertaining. If you need help figuring out the best way to boost business with data, you know where to find us.
References
- Fader, P. S., Hardie, B. G. S., & Lee, K. L. (2005). RFM and CLV: Using Iso-Value Curves for Customer Base Analysis. Journal of Marketing Research, 42 (4), 415–430. http://brucehardie.com/papers/018/fader_et_al_mksc_05.pdf
- Gomez, Carlos A., and Neil Junt. “The Netflix Recommender System: Algorithms, Business Value, and Innovation.” ACM Transactions of Management Information Systems, vol. 6, no. 4, 2016, pp. 1-19. https://doi.org/10.1145/2843948.